Computer Science AS
Introduction Information Representation Communications Communications 2 Hardware Logic Circuits Processor Fundamentals Assembly Language Monitor & Control System Software Security, Privacy & Data Integrity Ethics DatabasesAS Practical
Algorithm Data Structures and more Software developmentComputer Science A2
Data Representation File Organisation Advance Logic GatesInternet Virtual Machines System Software Encryption & Security Artificial IntelligenceA2 Practicals
Binary Search Linear Search Bubble Sort Insertion Sort Combined Algorithm Stacks Queues Linked List Binary TreeMore
Reference Pastpaper Questions
Stages of Software Development
Features provided by a IDE or IDLE
There are some features provided by an IDLE editior which helps you to create programs more easily:
- Pretty printing
- Context-Sensitive prompt
- Dynamic Syntax check
- Expanding and collapsing code blocks
- Debugging
- Analysis/Requirements
- Design
- Implementation or Coding
- Testing
- maintenance
- Syntax errors
- Logical errors
- Run-time errors
- Corrective maintenance
- Adaptive maintenance
- Perfective maintenance
- Waterfall Model
- Iterative or incremental model
This color codes or changes the style of the code for keywords and other components such as functions,comments and identifiers which helps us to identify each type easily
These provides suggestions for identifiers or the choice of keywords when typing the code
The editior checks for syntax errors even before the code is run and alerts the user
These are used to collapse codes such as functions classes or similar code to a single line so it can help reduce the code in the editor and make it easier to scroll
IDE provides debugging features such as breakpoint to help debug the code
Stages of Software development
We will talk about each step in depth
There are 5 stages of software development
Identifying the problem and the purpose of your program. Also the requirements it needs such as hardware and software
These stage identifies the efficient solution to the problem the algorithm offers. The problem can be solved by either breaking down the large problem to smaller sub problems(stepwise refinement) or expanding on a subproblem to create the full complete program( bottom - top )
This stage deals with the design of the solution(algorithm) and any datastructures and identifiers that are used.
In order words, this deals how the code must work
This is also the stage where the code is written in pseudocode or represented using structured charts
This stage identifies which programming language is appropriate for the algorithm and this stage is the where the coding is done by the software developers
This tests the program to check for any errors
There are many testing methods to make sure the program is error free before it is released
After the code is released for the users to use, errors and bugs may arise and also the program may have to improve on somethings
We will now see each stage in detail
Analysis
Not required in detail
Design
This stage deals with how the code must be written
Usually the solution or the algorithm must be wriiten in pseudocode
The program may contain sub-tasks called modules and a structured chart is used to show the link between these modules
For example , if your program was to perform additions of two numbers, then one module could be used to enter the two numbers and the other module could be to calculate the total ( Just remember this is a very simple code ).
So the structured charts is the graphical representation of how data should flow from one module to another
So the Input module can take two values and send it to the totalling module
If you don't know what are structured charts, I recommend you to watch the video section below which explains the key things in structured charts
A thing to remember is that structured charts is a collection of modules linked to each other. And so to represent it in pseudocode we need to call the procedures
Coding
This is very simple and involves writing the algorithm in the most suitable language
Python is a powerful language which uses an interpreter.
It can be used to produce many games and graphics. However, we use C++ to write games. This is because C++ runs extremely fast compared to python
Testing
There are 3 Types of errors:
These are errors which the program statements doesn't follow the rules of the programming language
The code may have wrong grammer or wrong keywords which are not recognised by the language
These errors are usually identified by compilers and interpreters. However, interpreters identify them when the line is executed, so the whole code must be executed
Error in the design of the code which gives us unexpected results
If the program doesn't function as it is supposed to or intended to then there is a logical error
It will give wrong or unexpected outputs
Errors which cause the program to freeze or crash. For example division by zero or memory overflow errors
These errors are identified when the program is executed and tested
Testing Methods
There are many testing methods which you have to know
Stub testing
This makes sure that a procedure is callable.
So the procedure contains an output statement to show that the procedure is callable when it is called from the main program
Black-box Testing
It is used and run by a person who has not seen the algorithm
So this compares the expected results with the actual results the program outputs.
White-box testing
It is tested by a person who has seen the program code and so the program is tested in every aspect by using specific input data called test data
So this is done by carefully testing the data by putting extreme, erroneous and normal data.
Normal data - is data within an acceptable range
Extreme data - is data which are boundary values but must be accepted/correct
Erroneous data - is data out of an acceptable range. So it is considered wrong and not accepted
Then the algorithm is traced using a tracing table which stores the current contents of the variable as the program executes
Integration
Once the individual modules are tested by the software developers and are error free, the collection of modules must work properly as a whole complete system. This is known as integration testing
As this checks makes sure that data is passed to the right modules
This is done by incrementing the modules to the testing. So it makes it easier to identify the errors between modules
Alpha testing and Beta testing
Alpha testing is when the program is heavily tested in house by dedicated testors
In-house means testing done within the company or the organisation
Beta testing is when the program is issued to a limited number of users which use the program for their use and reports any feedbacks or errors to the company
Acceptance testing
Softwares which were designed for a specific customer will receive the program and test to see if it meets their specific requirements. This is known as acceptance testing.
If it does meet the requirements then the customer will sign off the software completion
maintenance
maintenance could mean alot of things, so we will discuss 3 types of maintenance
maintenance in which errors/bugs are identified and corrected
When the program is released and used by users, errors or bugs may arise from the use of the program. This must be identified and corrected
Ammending the program so it contains enhanced functionaility and can respond to changes in requirements
Such as a program may have to be adjusted to meet the new updated requirements
This makes sure the program is improved to have better performance and maintainability
maintainability means the program is more efficient and easily maintainable
Also the performance improvements could include faster execution
Methods/Models of Software development
There are 3 ways the company can approach to develop softwares:
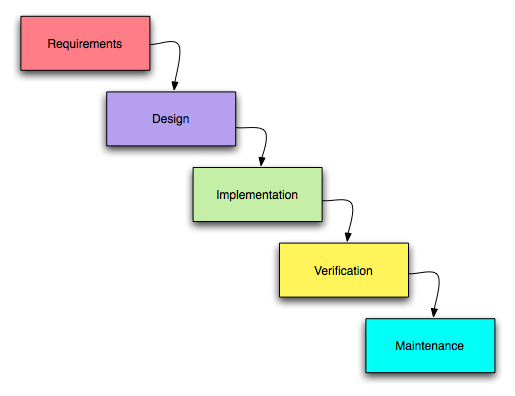
This is a methodology which ensures the requirement or analysis of the program is clearly identified before the program is built
The development occurs in stages where each stage is completed before it goes to the next stage. This is because the output of the current stage is the input of the next stage
There are some advantages of the waterfall method:
1. Each step must be completed before the next step is handled so it makes it more simpler
2. Very easy to manage and follow and easier to understand
3. Used for small softwares where the requirements are easier to identify.
There are also some disadvanatages
1. It is not suitable for large softwares as the requirements are very large
2. Not suitable for long ongoing projects
3. Can not accommodate changing requirements. It is usually costly
4. A working testable program is made only at the later stages of the development
The software developers doesn't require to have the complete requirement of the system but focuses on the sub-set requirements of the system. Then there are repeated reviews for further requirements which eventually leads to the complete system being built
A good example is when your application receives updates which the features of the system improves
There are some advantages you need to know:
1. There is working model of the system earlier in the stages of development so errors and bugs are found earlier. So this is way easier than correcting errors later
2. Parallel development can be planned
3. Less costly to change the scope or the requirements
4. Suitable for large programs which can be broken down to sub tasks
5. Each increment produces an operational product
6. Allows customers to test the updated increments and give feedback to the company
There are some disadvantages
1. This only can be used for softwares which can be broken in to sub task
2. Requires more resources
3. For identifying incremental requirements it may require you to define the complete requirement to some degree
4. There might be errors in the design of the complete system as the whole system requirement is not fully understoood in the beginning
Rapid application development (RAD)
This involves building and testing modules in parallel and releasing them as proto-types
So these prototypes are part of the complete system and are tested by users to see if they meet the user requirement and feedback is given to the company
The company then improves and adjusts the module depending on the feedback they receive and integrate them to produce the complete system
The main difference between iterative and RAD is that RAD requires the user(customers) involvement throughout the complete cycle where as iterative implements and tests each increments and releases each increment at a time
Also RAD releases the modules as prototypes.
RAD requires very little planning and analysis as the requirements are based on the customers(feedback)
There are some advantages:
1. Faster development
2. Encourages customer feedback as the model depends on the customers requirement
3. Can accommodate changing requirements
4. Productivity increases with fewer people
5. As the implementation of modules occur at the start, it can be used to find integrating errors more easily and faster
6. Produces reusable components such as modules
There are also disadvantages:
1. Only program which can be modularised can follow the RAD model
2. Requires a team of specialised software engineers
3. Requires the user involvement troughout the development cycle
Recommended
These are things you might like. Clicking these ads can help us improve our free services in the future...
End of Chapter Videos
Collection of Videos to Support Your Understanding.
Remember these videos are handpicked by me and I feel these are the best ones out there. But I constantly update this list for each chapter. The Youtubers are more than welcome to contact me.
Also, don't forget to Subscribe to our Youtube channel - Wiscus
Watch