Computer Science AS
Introduction Information Representation Communications Communications 2 Hardware Logic Circuits Processor Fundamentals Assembly Language Monitor & Control System Software Security, Privacy & Data Integrity Ethics DatabasesAS Practical
Algorithm Data Structures and more Software developmentComputer Science A2
Data Representation File Organisation Advance Logic GatesInternet Virtual Machines System Software Encryption & Security Artificial IntelligenceA2 Practicals
Binary Search Linear Search Bubble Sort Insertion Sort Combined Algorithm Stacks Queues Linked List Binary TreeMore
Reference Pastpaper Questions
System Software & Compilation A2
Kernel Software
The Kernel Software is the interface between the user and the hardware of the computer. It is a layer of the Operating System in which handles all the underlying functions of a computer
Input / Output Managements
When you connect an input or output device the operating system will do some very important functions:
1. Install the driver of the device
2. Handes any interrupts from the device
3. Handles in buffer signals
4. Handles any queue control signals
Due to high speeds of the operating system, it is very rare that an input or output device will communicate directly with the operating system. So sometimes the input and output signals are stored in buffer in the main memory and sent to the processor only when the time slice for the input / output device starts.
This process of dividing time slices is called process scheduling or management which will be discussed in the next heading.
Process Scheduling
The reason we need this is because the cpu can only handle one instruction at a time. This is an important thing to remember which means that an algorithm must be used in order to decide which process or instruction is to be loaded to the CPU. This type of scheduling is called low-level scheduling.
The other type of scheduling is high level scheduling in which a decision must be made on what process can be stored in the main memory from the hard drive. Note that the Main memory can hold many processes or instructions but it is a small number as the storage of Main memory is small
What is a process?
This is the AS level definition
An execution of a program
This is the definition for A2
A program in memory with associated PCB
What is a PCB block ( program control block )? It is block that holds the required data for the process. A PCB is like an array of data that has the required data for the process to executed successfully
Process States
There are 5 stages of a process in which we will discuss about:
- New Stage
- Ready Stage
- Running Stage
- Waiting / Block Stage
- Terminated
- Non-Preemptive
- Preemptive
- Lexical Analysis
In this Stage, the process has just entered the main memory and is getting its associated data ( PCB ) to be ready to be running
The Process is ready to start running and performing it's task
The Process is running inside the CPU
In this Stage, the system is waiting for a input or output signal
The Process is completed and terminated
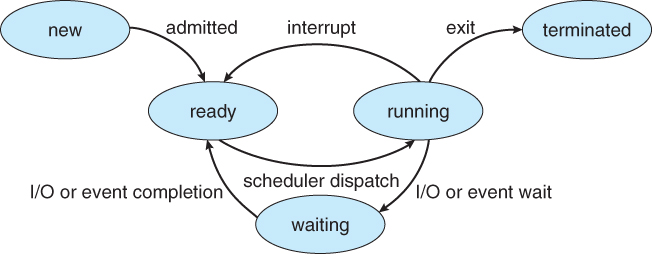
A good thing to remember is that the process must exist in the memory for the cpu to access it as the cpu has direct access to main memory only!
For the above diagram, an interrupt can be generated to move the state from running to ready or another input/output interrupt can be generated to move the state to the waiting state
High level Process Scheduling
There are two types of Scheduling algorithms depending on whether the priority of each task is considered or not!
This does not consider the priority of each task and does not halt the process half way but makes sure the full process is completed and then the next process is fetched
This is very time consuming and can be sometimes inefficient. For example, the cpu may have to wait for the printer to send signals and stay idle as it can only handle one task. So this does not allow for multi tasking!
Does consider the priority of each task and uses interrupts to halt processes and multitask. Which means each job recieves a time slice to execute the process.
Examples of Preemptive & Non-preemptive
The Idea is that the examples below can be used for both but their functions have to be changed. We can use:
1. First In First Out
2. Round Robin
3. LIFO
The reason why we can apply them for both is that the only difference is that rather than using whole processes in non-preemptive we use time slice or an allocation period for the preemptive
However, the below can only be used for Preemptive as they consider time as a factor
1. Longest Job First Out
2. Shortest Job First Served
Round Robin means a cyclic shift in which the process is given an equal time and once the time slice is done, it circularly moves to the next task
Memory Management
The Main memory has limited memory and sometimes the computer may require more of it. The way to solve this is to implement virtual memory
The idea is that the computer will allocate some of its storage as memory so it can act like RAM or Main memory. The only issue is that the speed of a hard drive is slower than the Main memory
When answering a question just remember these points:
1. Virtual Memory extends the RAM or increases the size of RAM
2. The Virtual Memory is divided into equal size pages
3. The Main memory is divided into equal size frames or page frames
4. The frame size is equal to the page size
5. A page table contains the process page number and whether it is present in memory and also the Physical (Main memory) Address and the corresponding Logical ( Virtual Memory ) Address
The New Cambridge A level Text Book confused me for days and I finally understood that the concept in the book was incorrect. I have verified this from trusted sources. The Book refers to the page as part of a process that is misleading the process size must indeed be the same as the frame but it's called a Job not a page
What is partitioning and Segmentation?
The idea is similar to pages and frames but, partitioning is the breaking down of memory to variable sizes whereas segmentation is breaking down of virtual memory to variable sizes!
What is Stored in the Page Table
In the recent past papers I noticed this question popped up, so I will simply tell you the points you need to write:
1. If the process is present in memory
2. Logical and Corresponding Physical Address
3. Time of Entry
Time of Entry is the digital time when the process entered the main memory. Note that this is not the length of time
Page Faults
Interrupts are generated all the time in the processor especially during the end of a time slice. However, there is a special type of error
If the processor requires a process, then it must be present in the Main memory as discussed before. If it is not present in the main memory then this condition is called a page fault. An interrupt is generated so the process is to be fetched from the virtual memory. If it is still not present, then the process can not be executed
Disk Thrashing
This is a very interesting situation and somewhat very easy to understand
When a large job is loaded from the virtual memory to the main memory and the loaded job needs to load another job from the virtual memory, in some cases both can't fit inside the main memory. But both jobs are dependent on each other and both must be loaded in the Main memory. But the Main memory can not do that and so there will be swapping of the two jobs between the Virtual and Main memory and as both are dependant on each other, this will lead to infinite loading called disk thrashing. Disk Thrashing could also occur for finite swapping but it is usually very large
Compiling
We have discussed compilers in the previous chapters. Here we will see the steps of compiling. There are 5 steps in compilations and these 5 steps fall under 2 categories
In this stage, the comments are removed, and also whitespaces and errors are detected and removed. Also, the identifiers and operators are separated and identified using tokens that are stored in the keyword table.
For example:
A + B = Total
A, B, Total + and = are lexemes
Look at the other example:
Total = (A*B)+C Total = ( A * B ) + C
Keyword & Symbol Table
The line of code is separated to lexemes. Each lexeme has a corresponding token which is stored in a keyword table. For example, operator and keywords and special lexemes are stored in the keyword table
In the symbol table, we record the identifiers and the corresponding data types. It is similar to an identifier table
It is sometimes misleading that the symbol table records identifiers and the keyword table records token. So please practice this!
More on Symbol tables are here
In this stage, the grammar of the language is understood and converted in a way that can be understood by the computer. This includes using a parse tree or syntax tree to determine order of calculation.
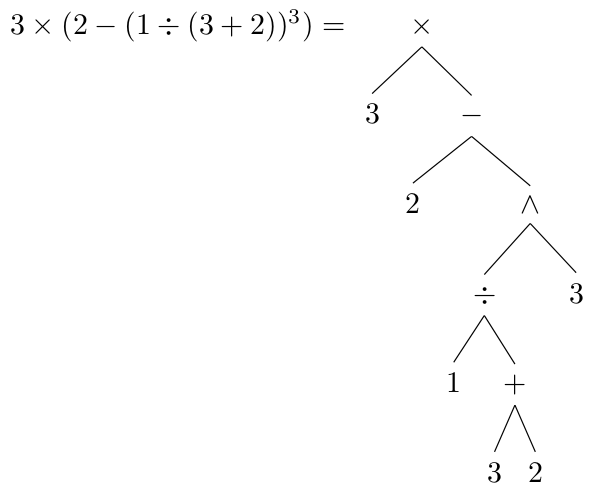
Also in the real world, we have rules of precedence in mathematics such as
A+ 2*B
By the laws of BIDMAS we do the multiplication first before additions. When converting this form to a way that doesn't require rules of precedence or brackets
A+ ( 2*B ) Is the infix form
A2B*+ Is the Post-Fix or RPN form
The RPN form doesn't need the requirement for rules of precedence or any brackets. Also the code can be read from left to right only
A basic understanding of converting RPN to Normal or Infix form is by doing the steps below
1. If it is a identifier or variable then push it to the stack
2. If it is an operator then pop the last two variables or values and record the value, example 23+ is 5
3. Keep repeating the process
Let us see an example:
Convert 23456*+/*3*
By doing the method above keep on repeating until you reach * then simplify the last 2 variables, Make sure you read from left to right, so when i mean last i mean the leftmost side
Convert 234(30)+/*3* Convert 23(34)/*3* Convert 2(3/34)*3* Convert ((3/34)*2)3* Convert (3/34)*2*3
We read from left to right so the infix form must have the correct value. The values on the right are placed on the right. For example:
If A+ B*C Then BC*A+ is not correct but ABC*+ is correct SO ORDER MATTERS!
To test your understanding convert D/((A*B)+C) infix to RPN/Postfix form
Reveal Answer
DAB*C+/
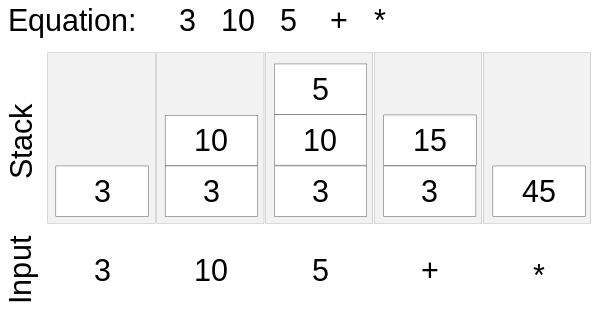
Solving RPN using a Stack
You can solve the RPN using the method above. When adding variables we add to the bottom of the stack. Then for each step, take a new column.
If it is an operator then pop the last or top two variable and record the value and so on. Keep repeating the process and read from left to right only
Here is an example:
Parse Tree Or Syntax Tree
The Syntax tree is a graphical representation of the RPN form. It shows the rules of precendence. The ones at the bottom leaves are done first and the nodes are the operators
BNF
This is Similar to the Syntax Analysis. In this, it handles the format of data
Some notations you need to remember are:
| The Or Symbol
<Variable> is an item
::= Assign or equals to
For example:
<Letter>::=A|B|C|D <Number>::=0|1|2|3 <Password>::=<Letter><Letter><Number><Number>
So in this case the password must start with 2 letters and have 2 numbers
So AC12 is a valid password but, AH12 is not as H is not an option in letters and also AHE2 is not valid as it must have 2 letters and 2 Digits also. Finally AA2 is also wrong
Is 33AA a valid password
See Answer Here
No, the numbers must be last...
Recursive BNF
If the person is able to enter as much as data items they want then they can use a recursive function. For example if the password must start with a letter but can have many digits or letters after that we show it like this
<Password>::=<Letter><Letter><Letter>|<Password><Letter>|<Password><Number>
The above shows the password must start with 3 letters and stop or continue adding futher digits or letters. Think of it as a value. Once the password has 3 letters it can be used as a new variable again and added with digits or letters
Is AAAA a valid password
See Answer Here
Yes, as there are 3 Letters of "A" and the next one can be a digit or a letter
Is AAA a valid password
See Answer Here
Yes, as there are 3 Letters of "A" and there is no need to add another one
It is good to remember these symbols and all and another thing to remember is that if the BNF has a certain symbol then we need to add them
23.33 <Value>::=<Number><Number>.<Number><Number>
Syntax Diagram
A Syntax diagram is the graphical representation of the BNF form. BNF is written in words where as in Syntax diagrams we need to draw diagrams. Below are the corresponding diagrams for each BNF notation or symbols
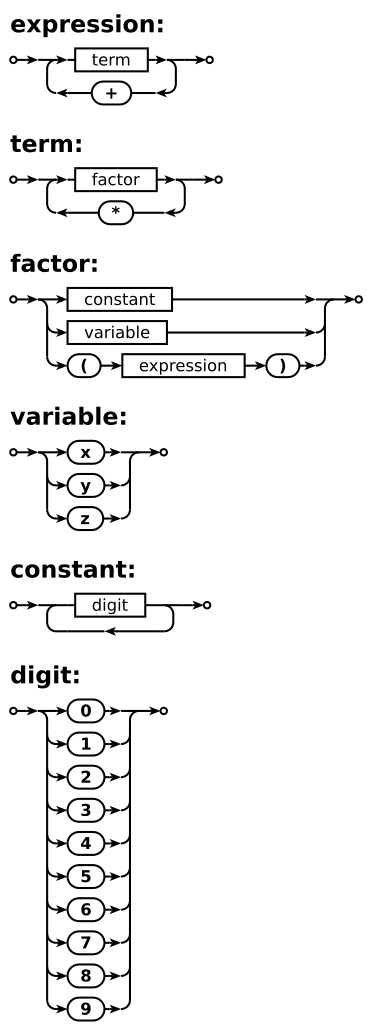
To show a recursive BNF then we use the one for constant above
This generates the final object code
This makes any improvements in the code to increase efficiency and reduce memory usage. For example,
LDD A ADD B STO C LDD C ADD E STO E #THIS IS A COMMENT
Could be simplified to this to reduce memory usage and lines of code
LDD A ADD B ADD E STO E
Also comments are removed here